


Vol. 1 No. 1 (2022)

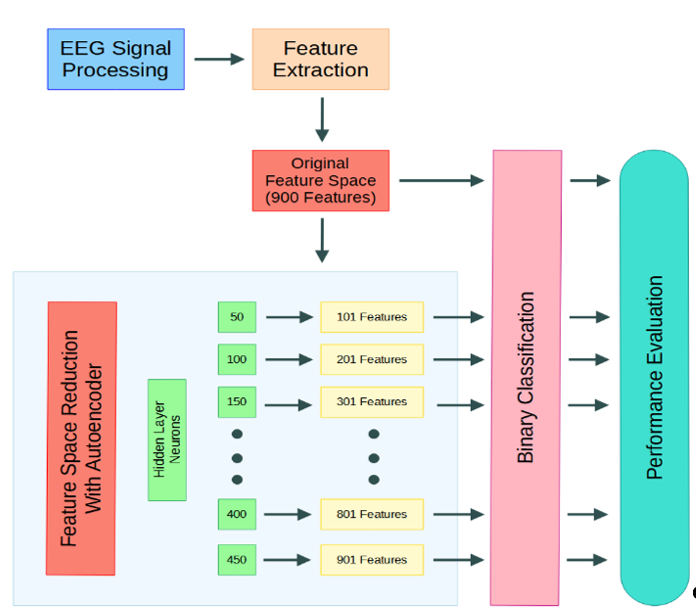
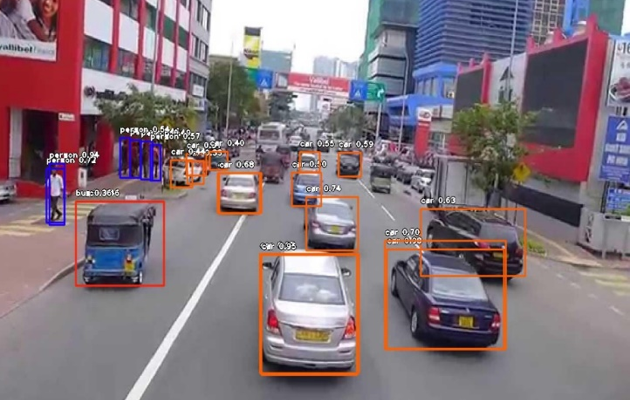
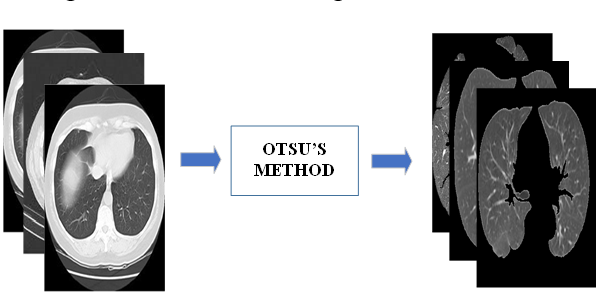
This inaugural issue of Intelligent Methods in Engineering Sciences (Vol. 1, No. 1, 2022) brings together multidisciplinary research on intelligent systems. Topics include assistive technologies for the visually impaired, BCI classification, autonomous vehicles, COVID-19 diagnostics from CT scans using transfer learning, and voice recognition-based educational game design.
Published:
2022-09-17

